 |
| Music |
| Computing |
| Info Arch |
| Theory |
| Practice |
| Glossary |
| Index |
Classification |
|
The procedure in which ideas and objects are recognized, differentiated and understood. In Information Architecture this process focuses on clarifying possible values for the aspects
Theory
Any given item can be classified in a number of different ways, the fact that a vehicle is red, is independent of the country it is to be found in. However some aspects may have unexpected relationships, for example if a vehicle is a van then in some countries it is much more likely to be white.
The simplest way to discuss the topic is to think about the item in terms of a class having a number of attributes. The attributes we are considering here can only have a restricted set of values, for example if the attribute is "colour" then the possible values are "red", "green", "white" and so on. This simple example illustrates some of the issues:
- What is a good list of values, if there are too few options then tints that are different get lumped together, too many and users get confused
- Is there a hierarchy of colours, for example "scarlet", "crimson" and "tomato" are all colour names that could be recognised as types of "red"
- There is a temptation to confuse these classification terms with normal usage. For example someone may complain that "black" is not a colour, however even if it isn't it can still a valid value. In contrast just because "scarlet" is normally a colour name does not make it valid in this usage
- For some purposes we want to define a well thought out list, for example by evenly spacing colours in HSV colour space we can provide a set of contrasting tones
- For other purposes any fixed list might not work, in these cases we may want to allow users to add their own colour definitions
The way we classify things often depends more on the goal we have in mind than on the things being classified. This is why collecting a large number of documents within a folder structure seldom works. The folder structure forces the user to apply a single classification scheme, which seldom matches the specific goal that an individual user has on a particular visit. A much better approach is to allow a number of different schemes (for example by storing references in a database, by automatically duplicating matetial into alternate hierarchies or by linking virtual directories into the information.
So what is being discussed here is really about the creation of a very specialised "language" with defined values that describe all the possible values. For most purposes it is important to be clear about how the terms are related. The gathering of terms with relationships between them is called Ontology. Many different systems have been used to create such schemes. The most important element is to have a clear definition of what the terms mean, and which relationships between terms are going to be documented. Unfortunately it is very easy to be vague about the details, which is one of the reasons why the word "Ontology" has such a bad reputation.
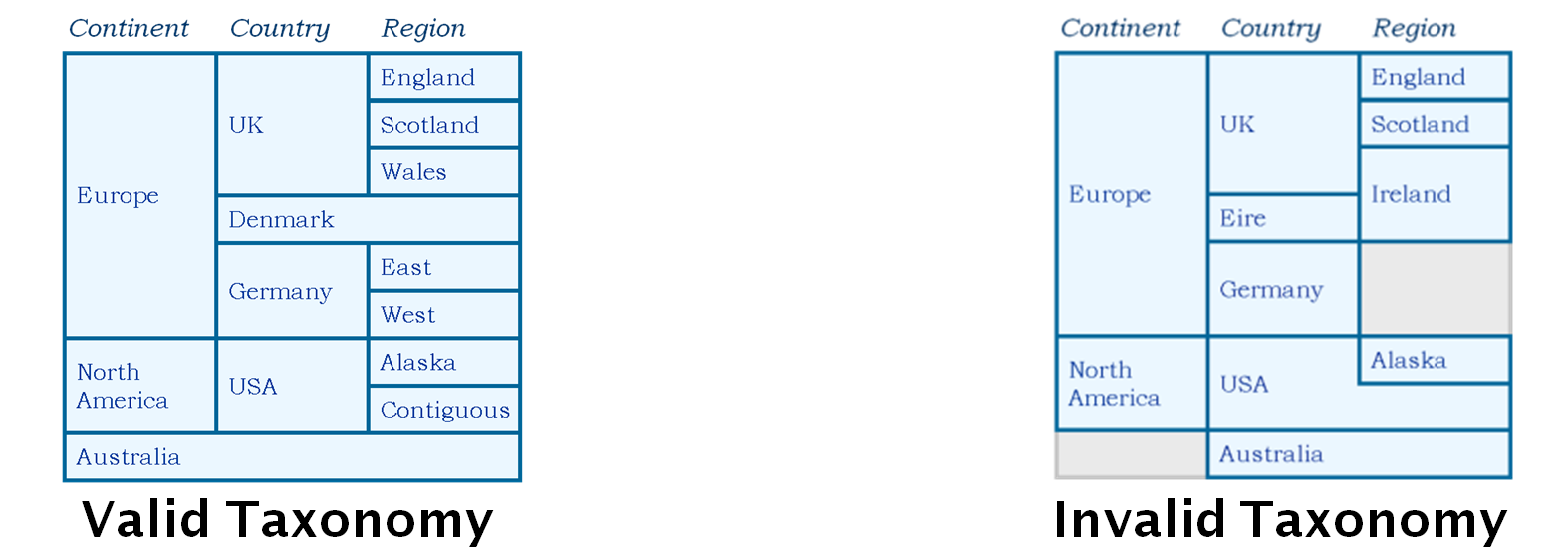
When deciding what the terms mean and how they are related one approach is to restrict them into a hierarchy. The diagram above shows how this may work. On the right it also shows some of the pitfalls that arise if such a classification scheme is:
- ambiguous: Alaska is both part of the USA and a region in its own right, and Ireland is within both the UK and Eire
- incomplete: Germany has no regions and Australia is not within a continent
If we have a scheme like that shown on the left then all the elements are well defined and their positions within the hierarchy are clear. Such a scheme is called a Taxonomy. For anything other than the simplest of classification schemes it is difficult, that is expensive, to create such a scheme.
For this reason some schemes are based on an outline and then extended interactivly by user participation, for example by users define their own tags. This approach creates a classification scheme called a Folksonomy. In areas where the potential benefit does not justify the investment required to develop a taxonomy this is often the only viable option. However the lack of standards almost always leads to an inconsistent incomplete and redundant scheme.
Practice
In practice the definition of possible values and the relationships between them is one of the biggest challenges that an information architect faces.
Rendition
There are a variety of ways to document classifications. The best approach depends on the type of classification scheme:
For a taxonomy it is easiest to maintain a database or spreadsheet that holds the classification and a short description. If there are less than about 30 terms then a simple picture, like that shown above, can also work well.
If you are constructing a folksonomy then the form will often be determined by the mechanism you use. For example a simple database or text file will often be required and produced by a web server.
If your ontology does not conform with either of those models then there are a variety of approaches to use. XML is the most obvious choice for holding the current state, although a database can also be used. Unfortunately none of the choices completely solves the issues and work in this field is prone to misunderstandings, overselling the benefits and difficult projects.
Implementation
Reducing each classification scheme to a list simplifies the way it is stored. During the early phases of a project the list of possible values can be kept in a text file, XML document or as a tab in a spreadsheet
Links to this page
The following pages link to here: Aspect, Checklist, Coverage, Cutter Classification System, Data Category, Data Migration, Dewey Decimal System, Folksonomy, Hierarchical, IA Best Practice, Identifier, Implementing IA, Inference, Karnaugh Map, Library of Congress Classification, Library Science, Library System, Statistics, Taxonomy, Uses for IA, Web Crawler, Wiki